Section 10.1 What is a text?
Throughout this book, we have looked at very small units of language – morphemes, words, phrases and sentences. In real life, we are more likely to encounter longer stretches of language, such as the following, which is taken from the Wikipedia page shown in Figure 10.1.1
Text 1Apple corer(1) An apple corer is a device for removing the core and pips from an apple. (2) It may also be used for similar fruits, such as pears or quince.(3) Some apple corers consist of a handle with a circular cutting device at the end. (4) When pushed through the apple, it removes the core to the diameter of the circular cutting device. (5) The core can then be removed from the apple corer.(6) Another type of apple corer can be placed on top of the apple and pushed through, which both cores and slices the apple. (7) This is also often called apple cutter or apple slicer.(8) An apple corer is often used when the apple needs to be kept whole, for example, when making baked apples. (9) Apple slicers are used when a large number of apples need to be cored and sliced, for example, when making an apple pie or other desserts.―Source: Wikipedia, s.v. apple corer (2020-10-28)
In everyday language, we would call it a text, rather than (as we just did), “a stretch of language”. But why?
The (everyday) word text has a range of related meanings, all of which apply here. First, text refers to the linguistic part of a body of writing, rather than, for example, the pictures accompanying it. In this sense, everything on the page except for the Wikipedia logo and the two photographs are text. Second, it refers to a “body” of writing, i.e., a stretch of language that is separated from other stretches of language in some way.
Subsection What is a text?
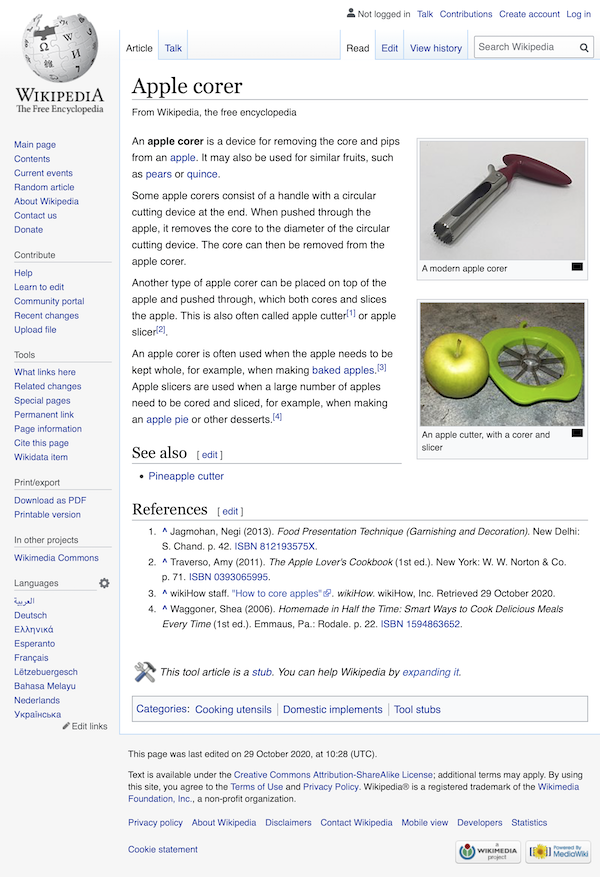
The Wikipedia entry for Apple Corer, illustrating the layout of the webpage and the position of the article text among the other elements of the web page. These are described in the main text of the chapter in detail.
Looking at Figure 10.1.1, the stretch of language cited above is separated from the rest of the written words appearing on the same webpage by various types of boundary signals — it appears in a white box, while much of the other written material occurs in a grey box surrounding it or in grey boxes containing pictures. Other boundary signals are more subtle. For example, there are three sections within the white box, that are signaled by lines with writing in a larger font above each line — the words Apple corer in a very large font size and the phrase See also and References in a slightly smaller font size that is still much larger than that in which the passage cited above appears. In other cases, there are grey square brackets (around the word edit) or a little tool icon (next to the notice “This tool article is a stub. You can help Wikipedia by expanding it.”). There is also the phrase “From Wikipedia, the free encyclopedia”, which appears in a slightly smaller font than the passage cited above and which is separated from it by a larger stretch of white space than those stretches occurring within the passage.
Such external boundary signals (which may even be physical boundaries, such as the edge of a printed page, or the covers of a book), as well as the relationship between different types of visual information that make up a book, webpage, newspaper, etc. (text, images, pictograms, lines and boxes of various colors, etc.) are an area of research in themselves and are studied by scholars interested in the multimodal contexts in which language often occurs.
In linguistics proper, we are more likely to be interested in what is left when all these things are subtracted, i.e., the cited passage itself, which we might refer to as “the (actual) text of the article”. This passage constitutes a text with respect to two aspects that are inherently related to language and that remain constant when we remove the passage from one context (such as the web page shown in Figure 10.1.1) and place it in a different context (such as the document you are reading right now, which could be a different web page, an ebook or even a printout).
The first of these aspects concerns the content: The passage counts as a text rather than a sequence of unrelated clauses because it deals with a single topic (devices for removing apple cores) in a systematic way. Every clause in the passage contributes information about this topic, systematically building on information provided by previous clauses. For example, the first clause defines in general terms what an apple corer is (a device meant for removing cores from apples), and the second clause builds on this definition by pointing out additional uses (removing cores from other fruits with a core). In linguistics, this property of texts is referred to as coherence.
The second of these aspects concerns the form: The passage counts as a text because the individual clauses contain linguistic expressions that connect them to each other. Some of these expressions are dedicated to signaling specific types of relations — for example, the word also in the second clause signals that the information in the second clause is an addition to the information in the first clause (dictionaries give the meaning of also as “in addition to”). Other expressions do not signal specific relations, but are limited in their occurrence to clauses that are connected. For example, the pronoun it in the second clause refers to the apple corer, but we only know this because the apple corer is explicitly mentioned in the first clause. Similarly, the phrase other fruit can only occur in a context where at least one fruit has already been mentioned (in this case, the apple in the first clause. In linguistics, this property of texts is referred to as cohesion, the type of expressions just mentioned are referred to as cohesive devices.
Subsection
CC-BY-NC-SA 4.0. Written by Anatol Stefanowitsch